认识分布式存储
1 | 分布式存储系统,是通过网络将数据分散存储在多台独立的设备上。 |
分布式存储系统的特性
- 可扩展性:节点扩展后旧数据会自动迁移到新节点,实现负载均衡,避免单点过热的情况;水平扩展只需将新节点和原有利群连接到同一网络不会对业务造成影响;当节点被添加到集群,集群系统的整体容量和性能也随之线性扩展。
- 低成本:
- 高性能
- 易用、易管理
1 | 分布式存储系统的挑战主要在于数据、状态信息的持久化,要求在自动迁移、自动容错、并发读写的过程中保证数据的一致性。 |
存储分类
- 本地存储:硬盘,不能在网络上用,ext3、ext4、xfs、ntfs。
- 网络存储:网络文件系统,共享的都是文件系统。nfs、hdfs、glusterfs(后2个都是分布式网络文件系统)
- 共享裸设备:块存储,cinder、ceph(可作为块存储、对象存储、分布式网络文件系统)、SAN(光纤交换机存储)
- 分布式存储:集群
分布式存储分类介绍
- Hadoop HDFS: 大数据分布式文件系统
1 | hadoop的存储组件,hdfs是一个高度容错性的系统,能提供高吞吐量的数据访问非常适合大规模数据集上的应用。 |
- Openstack的对象存储Swift
1 | Swift目的使用普通硬件来构建冗余的、可扩展的分布式对象存储集群,存储可达PB级。Swift是python开发。 |
- GlusterFS
1 | GlusterFS是一种全对称的开源分布式文件系统,全对此是指GlusterFS采用弹性哈希算法,没有中心节点所有节点全部平等。GlusterFS配置方便、稳定性好,可轻松到达PB级别容量,数千个节点。 |
- 公有云对象存储
1 | aws s3; azure bolb; 阿里云 oss;腾讯云 cos;华为云 obs等 |
ceph介绍
ceph简介
1 | ceph使用c++语言开发 |
优势
1 | 高可扩展:使用普通x86服务器,支持10~1000台服务器,支持TB到EB扩展。 |
ceph架构
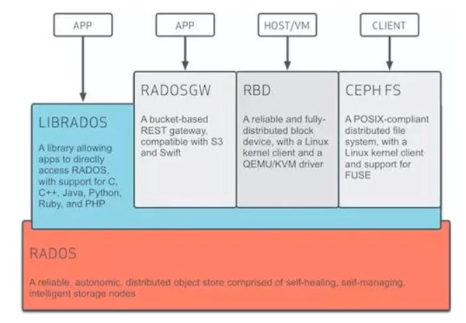
1 | 基础存储系统 |
ceph基本组件
- ceph主要三个组件
1 | Osd:用于集群中所有数据与对象的存储,处理集群数据的复制、恢复、回填、再均衡。并向其他osd守护进程发送心跳,然后向Mon提供一些监控信息。当ceph存储集群设定数据有两个副本时(一共存2份)则至少需要2个OSD守护进程即2个osd节点,集群才能达到active+clean状态。 |
- ceph结构包含2个部分
1 | ceph client:访问ceph底层服务或组件,对外提供各种接口。比如对象存储接口、块存储接口、文件缓存接口。 |
Ceph存储种类及其应用场景
块存储
1 | 典型设备:磁盘阵列、硬盘 |
文件存储
1 | 典型设备:FTP、NFS服务器 |
对象存储
ceph同时提供对象存储、块存储和文件系统存储三种功能,满足不同应用需求。
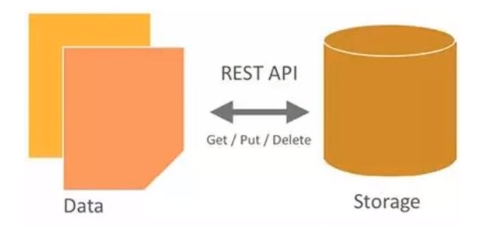
1 | 为什么需要对象存储? |
1 | 什么是OSD? |
ceph数据的存储过程
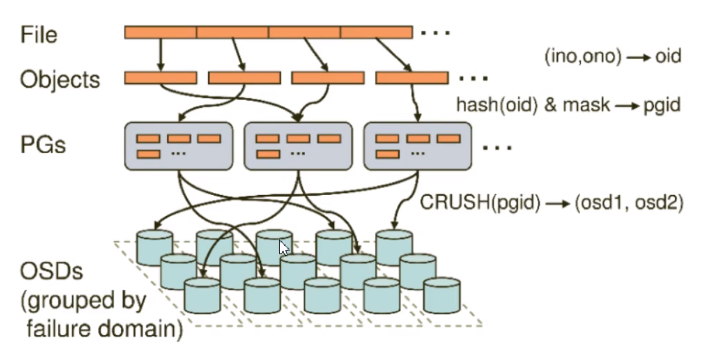
1 | 无论使用哪种存储方式(对象、块、网络挂载),存储的数据都会被切分成对象(objects)。 |
ceph名词介绍
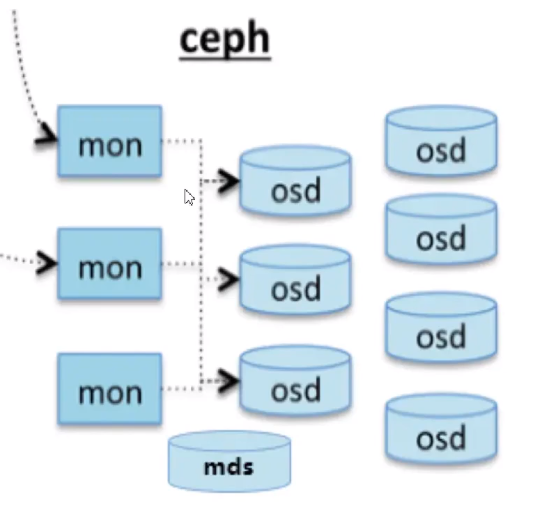
1 | Monitor:监控整个集群的状态,维护集群的cluster MAP二进制表,保证集群数据的一致性。 |

