Pod生命周期
下图就是Pod的生命周期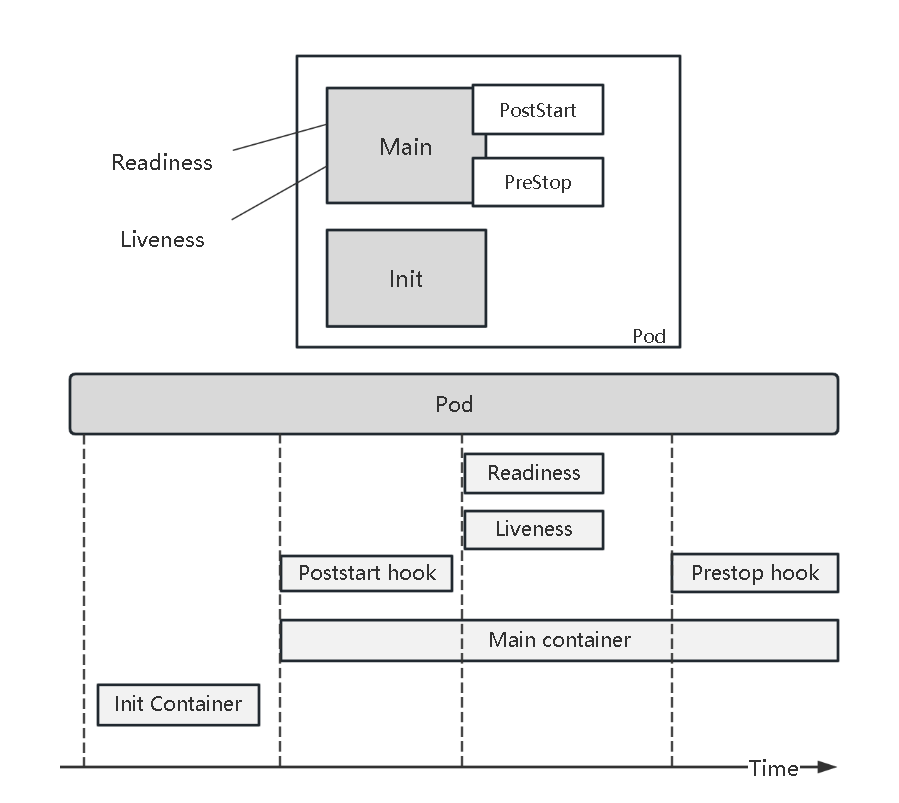
1 | Init container一定要在Main container之前执行,而且成功之后才会开始Main container。如果他失败pod也会失败,所以可根据此特性来做初始化的工作。 |
1 | apiVersion: v1 |
1 | 2个container可以共享一个存储volume,通过init container把数据准备到这个共享空间的路径上,main container就可以在这个存储上加载数据。 |
与PostStart对比
- poststart是异步执行的
- poststart过程不能保证在container的入口点前执行完成
- container的状态在poststart过程完成后才会被置为running
1 | 如果在pod中包含多个container,当我们需要某个container先完成启动就绪,就绪完成后才继续下一个container的创建,那么就可以在前一个container中加一个postStart。 |
健康检查
- livenessProbe:存活性探针,判断容器是否存活健康,不满足健康条件那么kubelet将根据pod设置的restartpolicy来处理。
- readinessProbe:就绪探针,判断容器内程序是否健康能正常对外提供服务。异常则通过enpoint列表剔除此pod。
- startupProbe:启动探针,主要解决上面2种无法更好判断程序是否启动、存活。StartupProbe探针只是在容器启动后按照配置满足一次后,不在进行后续的探测。
1 | startupProbe在Container启动时就开始工作,它确保该Container一定可以启动成功。 |
1 | livenessProbe: |
QoS 和 Priority
1 | # Priority 关于调度时 |
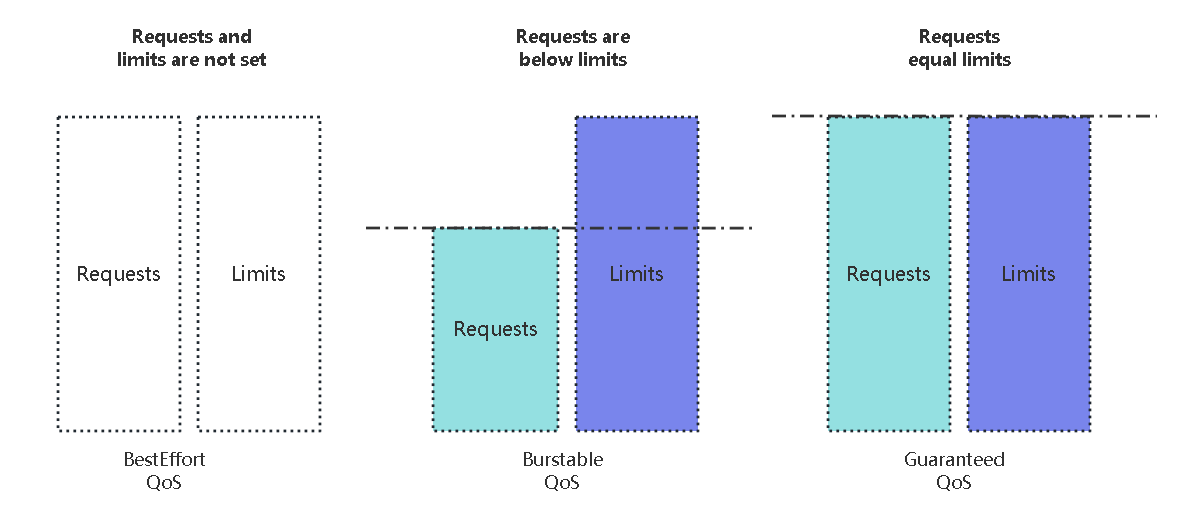
1 | 当一个node上有很多pod在运行,可能会出现node硬件不够用的情况。哪些pod会杀死哪些会保留,这个才是QoS。 |
Affinity 和 Taint
1 | Affinity亲和性是从pod的视角去看怎样的node适合我来运行;Taint是从node的角度来看自己可以运行什么样的pod,兼容了node上的taint的pod才可以被调度到node上。 |

